An Ode to Set Intersection

This here is Norman Casagrande, last.fm’s former head researcher and my former mentor. The facial expression seen here is one of my favorites. It’s usually accompanied by some questionably-translated Italian aphorism, ”You know, Erik, that is like the ox saying ‘horned’ to the donkey.”
This smarmy smile also usually means I’m about to learn something new. I saw it my very first day at last.fm. Norman was describing to me various gears and nozzles that power last.fm’s recommendations, and when he showed me the code that compares two musical items, I stopped him. I saw my chance to strike.
Set Intersection
Set intersection is a delightful little haiku problem in computer science. It’s simple, elegant, and is ubiquitous in search engine tech, collaborative filtering mechanisms, various types of matrix math… probably other places, too! Its most basic implementation is linear in complexity, and most people are happy with linear performance here. But as I studied the guts of Norman’s recommendation engine, I saw my first opportunity to unleash unspeakable power!
“Norman, what if I told you that there are set intersections much more efficient than this? In fact, I know of one that uses a search algorithm that is…”, I whispered almost breathlessly, “log-log!”
“Ehhh, you can try but I don’t think it will be faster. But you throw the spaghetti at the ceiling propeller and we will see what stays there.” And out came that infuriating smile.
So I set about to wipe that smile off Norman’s face. I was going to write the Rolls-Royce jet engine of all set intersection algorithms.
Binary and Interpolation Search
To write my code I drew from the experience I’d had at a job interview with Google some time before. A smart scientist had quizzed me about interpolation search, a way of finding elements in sorted sets by making educated guesses as to their location. He claimed it had contributed greatly to the performance of operations at Google, so I was sure it could do the same for me.
In turn I’d found a really excellent paper on set intersection, A Fast Set Intersection Algorithm for Sorted Sequences. This paper proposes the following algorithm:
- Pick the median element, A, in the smaller set.
- Search for its insertion-position element, B, in the larger set.
- If A and B are equal, append the element to the result.
- Repeat steps 1-4 on non-empty subsets on either side of elements A and B.
The paper showed that this algorithm does particularly well when one set is smaller than the other. Just to be sure, I wrote code to count the number of comparisons for three kinds of set intersection: plain old linear set intersection, the paper’s set intersection using double binary search, and my own variant using interpolation search.
View/download the source for this experiment from my themas github repository. You can profile the algorithms on uniform random data by building the project and running:
hexdump -e '1/4 " %u"' /dev/urandom | ./set_intersection_profile binary compares 100000 0.1 1.0 0.1 20
The results were exactly what I’d hoped, looking at the number of comparisons as I varied the ratio between the two set sizes:
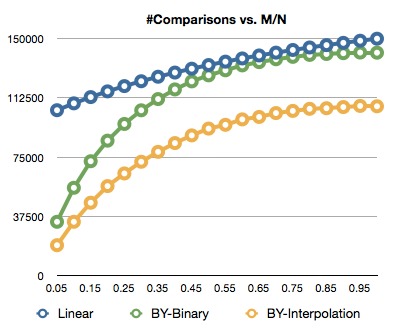
Not only did the interpolation intersection use far fewer comparisons in the case where M « N, but it performed better than linear everywhere else, too! Armed with this knowledge, I was ready to take Norman down.
To be continued!
p.s. For the observant programmer that is curious as to why the linear intersection’s line isn’t flat in the graph above, see this commit and maybe read about __builtin_expect. You’ll figure it out!